Lately, I’ve been more interested in learning about emulators and interpreters, down to the way that CPUs work at a low level. In university, the furthest down we got was C++ and we didn’t spend that much time there, so everything under that has always felt a little like black magic to me. To overcome that, I took a look into what it would take to write a toy emulator.
After briefly considering an NES emulator as my first project, I discovered the CHIP-8 VM and decided that would make a really neat first project. There are lots of resources for the CHIP-8 and it’s also a simple implementation, which means it can be done over a weekend or even faster.
I decided to write the emulator using Rust, a systems programming language that I’ve been dabbling in on and off whenever I feel like taking a break from Java. In the past, I would have dabbled in C or C++ but as time goes by, I feel that it makes more sense to focus on Rust.
Why?
Like C and C++, Rust compiles down to native code and runs without the overhead of a VM while also giving you full access to the platform underneath. Unlike C and C++, it also has some nice features that make it feel modern and fresh, like memory safety without garbage collection, super-charged enums, and a great build system that has built-in support for dependencies, unit testing, and more.
In fact, the only real beef I have with Rust is that it’s still young, so its support for mobile development is not quite up to par with the C and C++ support provided by Apple and Google. I’m sure this will improve with time. (After spending some time with Swift, I would also wish for no semicolons and maybe nicer optional unwrapping, but, at least with the semicolons, that ship has probably already sailed. :))
By writing the interpreter in Rust and taking advantage of the unit test features, it was very easy to build up the CHIP-8 VM, and I only ended up with a couple of pesky logic bugs due to being unsure about the implementation in a couple of places and due to a misuse of the slicing syntax.
Once I was done with the Rust implementation, I just copy-pasted the whole thing into Javascript, which you can check out at the end of this post. The code is available on GitHub, and here are a couple of other implementations you can also check out:
I would also recommend checking out nand2tetris, a really interesting course which teaches you how to build your own toy CPU from NAND gates. The course can be audited for free on Coursera.
In the future, instead of copy/pasting to JS, I might be able to just compile straight to WebAssembly:
John’s book is designed to teach a complete programming novice how to code by building game-based projects in Java. There are four projects in the book of steadily increasing complexity, with the last being a neat Snake clone with online leaderboards and achievements.
John has been hard at work, and also has another book due for publication in June titled Android Game Programming By Example which also focuses on game development. In this book, you’ll learn how to build three different 2D games, including an OpenGL ES 2 Asteroids clone, and a multi-level retro platform game.
On top of these two books, John has even been working on a website for game coding beginners with Java tutorials, information on game coding essentials, and he even has C++ tutorials in the pipeline. There’s a neat tutorial there on building a Breakout clone from scratch, and the projects are all based on Android Studio so everything is following the latest standards in the Android development world.
I’m happy to see what John has been able to create and look forward to seeing the site grow!
There’s been a lot of changes in the graphics programming community, with Google’s latest version of Android now supporting OpenGL ES 3.1, which brings support for compute shaders, as well as an Android-specific extension pack which adds support for additional features. Apple has chosen to go the proprietary route by remaining with OpenGL ES 3.0 for now and by introducing Metal, a new API which promises to increase performance and reduce driver overhead.
Here are some more links for your fall reading:
Tri-morph – A first game by a reader of Learn OpenGL ES.
In my previous post on this topic, A performance comparison between Java and C on the Nexus 5, I compared the performance of an audio low-pass filter in Java and C. The results were clear: The C version outperformed, and by a significant amount. This result brought more attention to the post than I was expecting; some of you were also curious about RenderScript, and I’m pleased to say that Jean-Luc Brouillet, a member of Google’s RenderScript team, got in touch with me and generously volunteered an implementation of the DSP code in RenderScript.
With this new code, I refactored the code into a new benchmark with test audio data, so that I could compare the different implementations and verify their output. I’ll be sharing both the code and the results with you today.
Motivations and intentions
Some of you might be curious about why I am so interested in this subject. 🙂 I normally spend most of my development hours coding for Android, using Java; in fact, my first book, OpenGL ES 2 for Android: A Quick-Start Guide, is a beginner’s guide to OpenGL that focuses on Android and Java.
Normally, when I develop code, the most important questions on my mind are: “Is this easy to maintain?” “Is it correct?” “If I come back and revisit this code a month later, am I going to understand what the heck I was doing?” Since Java is the primary development language on Android, it just makes sense for me to do most of my development there.
So why the recent focus on native development? Here are two big reasons:
The performance of Java on Android isn’t suitable for everything. For critical performance paths, it can be a big competitive advantage to move that code over to native, so that it completes in less time and uses less battery.
I’m interested in branching out to other platforms down the road, probably starting with iOS, and I’m curious if it makes sense to share some code between iOS and Android using a common code base in C/C++. It’s important that this code runs without many abstractions in the way, so I’m not very interested in custom/proprietary solutions like Xamarin’s C# or an HTML5-based toolkit.
It’s starting to become clear to me that it can make sense to work with more than one language, and to choose these languages in situations where the benefits outweigh the cost. Trying to work with Android’s UI toolkit from C++ is painful; running a DSP filter from Java and watching it use more battery and take more time than it needs to is just as painful.
Our new test scenario
For this round of benchmarks, we’ll be comparing several different implementations of a low-pass IIR filter, implemented with coefficients generated with mkfilter. We’ll run a test audio file through each implementation, and record the best score for each.
How does the test work?
First, we load a test audio file into memory.
We then execute the DSP algorithm over the test audio, benchmarking the elapsed time. The data is processed in chunks to reflect the fact that this is similar to how we would process data coming off of the microphone.
The results are written to a new audio file in the device’s default storage, under “PerformanceTest/”.
Here are our test implementations:
Java. This is a straightforward implementation of the algorithm.
Java (tuned). This is the same as 1, but with all of the functions manually inlined.
C. This uses the Java Native Interface (JNI) to pass the data back and forth.
RenderScript. A big thank you to Mr. Brouillet from the RenderScript team for taking the time to contribute this!
The tests were run on a Nexus 5 device running Android 4.4.3. Here are the results:
Results
Implementation
Execution environment
Compiler
Shorts/second
Relative run time
(lower is better)
C
Dalvik JNI
gcc 4.6
17,639,081
1.00
C
Dalvik JNI
gcc 4.8
16,516,757
1.07
RenderScript
Dalvik
RenderScript (API 19)
15,206,495
1.16
RenderScript
Dalvik
RenderScript (API 18)
13,234,397
1.33
C
Dalvik JNI
clang 3.4
13,208,408
1.34
Java (tuned)
Art (Proguard)
7,235,607
2.44
Java (tuned)
Art
7,097,363
2.49
Java (tuned)
Dalvik
5,678,990
3.11
Java (tuned)
Dalvik (Proguard)
5,365,814
3.29
Java
Art (Proguard)
3,512,426
5.02
Java
Art
3,049,986
5.78
Java
Dalvik (Proguard)
1,220,600
14.45
Java
Dalvik
1,083,015
16.29
For this test, the C implementation is the king of the hill, with gcc 4.6 giving the best performance. The gcc compiler is followed by RenderScript and clang 3.4, and the two Java implementations are at the back of the pack, with Dalvik giving the worst performance.
C
The C implementation compiled with gcc gave the best performance out of the entire group. All tests were done with -ffast-math and -O3, using the NDK r9d. Switching between Dalvik and ART had no impact on the C run times.
I’m not sure why there is still a large gap between clang and gcc; would everything on iOS run that much faster if Apple was using gcc? Clang will likely continue to improve and I hope to see this gap closed in the future. I’m also curious about why gcc 4.6 seems to generate better code than 4.8. Perhaps someone familiar with ARM assembly and the compilers would be able to weigh in why?
Even though I’m a newbie at C and I learned about JNI in part by doing these benchmarks, I didn’t find the code overly difficult to write. There’s enough documentation out there that I was able to figure things out, and the algorithm output matches that of the other implementations; however, since C is an unsafe language, I’m not entirely convinced that I haven’t stumbled into undefined behaviour or otherwise done something insane. 🙂
RenderScript
In the previous post, someone asked about RenderScript, so I started working on an implementation. Unfortunately, I had zero experience with RenderScript at the time so I wasn’t able to get it working. Luckily, Jean-Luc Brouillet from the RenderScript team also saw the post and ported over the algorithm for me!
As you can see, the results are very promising: RenderScript offers better performance than clang and almost the same performance as gcc, without requiring use of the NDK or of JNI glue! As with C, switching between Dalvik and ART had no impact on the run times.
RenderScript also offers the possibility to easily parallelize the code and/or run it on the GPU which can potentially give a huge speedup, though unfortunately we weren’t able to take advantage of that here since this particular DSP algorithm is not trivially parallelizable. However, for other algorithms like a simple gain, RenderScript can give a significant boost with small changes to the code, and without having to worry about threading or other such headaches.
In my humble view, the RenderScript implementation does need some more polishing and the documentation needs to be significantly improved, as I doubt I would have gotten it working on my own without help. Here are some of the issues that I ran into with the RenderScript port:
Not all functions are documented. For example, the algorithm uses rsSetElementAt_short() which I can’t find anywhere except for some obscure C files in the Android source code.
The allocation functions are missing a way to copy data into an offset of an array. To work around this, I use a scratch buffer and System.arraycopy() to move the data around, and to keep things fair, I changed the other implementations to work in the same way. While this slows them down slightly, I don’t believe it’s an unfair advantage for RenderScript, because in real-world usage, I would expect to process the data coming off the microphone and write that directly into a file, not into an offset of some array.
The fastest RenderScript implementation only works on Android 4.4 KitKat devices. Going down one version to Android 4.3 changes the RenderScript API which requires me to change the code slightly, slowing things down for both 4.3 and 4.4. RenderScript does offer a “support” mode via the support API which should enable backwards compatibility, but I wasn’t able to get this to work for me for APIs older than 18 (Android 4.3).
So while there are some issues with RenderScript as implemented today, these are all issues that can hopefully be fixed. RenderScript also has the significant advantage of running code on the CPU and GPU in parallel, and doesn’t require JNI glue code. This makes it a serious contender to C, especially if portability to older devices or other platforms is not a big concern.
Java
As with last time, Java fills out the bottom of the pack. The performance is especially terrible with the default Dalvik implementation; in fact, it would be even worse if I hadn’t manually replaced the modulo operator with a bit mask, which I was hoping the compiler could do with the static information available to it, but it doesn’t.
Some people asked about Proguard, so I tried it out with the following config (full details in the test project):
The results were mixed. Switching between Dalvik and ART made much more of a difference, as did manually inlining all of the functions together. The best result with Dalvik was without Proguard, and was 3.11x slower than the best C implementation. The best result with ART was with Proguard, and was 2.44x slower than the best C implementation. If we compare the normal Java version to the best C result, we get a 5.02x slowdown with ART and a 14.45x slowdown with Dalvik.
It does look like the performance of Java will be getting a lot better once ART becomes widely deployed; instead of huge slowdowns, we’ll be seeing between 3x and 5x, which does make a difference. I can already see the improvements when sorting and displaying ListViews in UI code, so this isn’t just something that affects niche code like audio DSP filters.
Desktop results (just for fun)
Just like last time, again, here are some desktop results, just for fun. 🙂 These tests were run on a 2.6 GHz Intel Core i7 running OS X 10.9.3.
Implementation
Execution environment
Compiler
Shorts/second
Relative speed
(higher is better)
C
Java SE 1.6u65 JNI
gcc 4.9
129,909,662
7.36
C
Java SE 1.6u65 JNI
clang 3.4
96,022,644
5.44
Java
Java SE 1.8u5 (+XX:AggressiveOpts)
82,988,332
4.70
Java (tuned)
Java SE 1.8u5 (+XX:AggressiveOpts)
79,288,025
4.50
Java
Java SE 1.8u5
64,964,399
3.68
Java (tuned)
Java SE 1.8u5
64,748,201
3.67
Java (tuned)
Java SE 1.6u65
63,965,575
3.63
Java
Java SE 1.6u65
53,245,864
3.02
As on the Nexus 5, the C implementation compiled with gcc dominates; however, I’m very impressed with where Java ended up!
C
I used the following compilers with optimization flags -march=native -ffast-math -O3:
Apple LLVM version 5.1 (clang-503.0.40) (based on LLVM 3.4svn)
gcc version 4.9.0 20140416 (prerelease) (MacPorts gcc49 4.9-20140416_2)
As on the Nexus 5, gcc’s generated code is much faster than clang’s; perhaps this will change in the future but for now, gcc is still the king. I also find it interesting that the gap between the best run time here and the best run time on the Nexus 5 is similar to the gap between C and ART on the Nexus 5. Not so far apart, they are!
Java
I’m also impressed with the latest Java for OS X. While manually inlining all of the functions together was required for an improvement on Java 1.6, the manually-inlined version was actually slower on Java 1.8. This shows that not only is this sort of code abuse no longer required on the latest Java, but also that the compiler is smarter than we are at optimizing the code.
Adding +XX:AggressiveOpts to Java 1.8 sped things up even more, almost closing the gap with clang! That is very impressive in my eyes, since Java has an old reputation of being a slow language, but in some cases and situations, it can be almost as fast as C if not faster.
The worst Java performance is 2.43x slower than the best C performance, which is about the same relative difference as the best Java performance on Android with ART. Performance differences aren’t always just about language choice; they can also be very dependent on the quality of implementation. At this time, the Google team has made different trade-offs which place ART at around the same relative level of performance, for this specific test case, as Java 1.6. The improved performance of Java 1.8 on the desktop shows that it’s clearly possible to close up the gap on Android in the future.
Explore the code!
The project can be downloaded at GitHub: https://github.com/learnopengles/dsp-perf-test. To compile the code, download or clone the repository and import the projects into Eclipse with File->Import->Existing Projects Into Workspace. If the Android project is missing references, go to its properties, Java Build Path, Projects, and add “JavaPerformanceTest”.
The results are written to “PerformanceTest/” on the device’s default storage, so please double-check that you don’t have anything there before running the tests.
So, what do you think? Does it make sense to drop down into native code? Or are native languages a relic of the past, and there’s no reason to use anything other than modern, safe languages? I would love to hear your feedback.
Two big names in the game development community are celebrating their achievements as they reach important milestones and bring their work to the community:
Android phones have been growing ever more powerful with time, with the Nexus 5 sporting a quad-core 2.3 GHz Krait 400; this is a very powerful CPU for a mobile phone. With most Android apps being written in Java, does Java allow us to access all of that power? Or, put another way, is Java efficient enough, allowing tasks to complete more quickly and allowing the CPU to idle more, saving precious battery life?
In this post, I will take a look at a DSP filter adapted from coefficients generated with mkfilter, and compare three different implementations: one in C, one in Java, and one in Java with some manual optimizations. The source for these tests can be downloaded at the end of this post.
To compare the results, I ran the filter over an array of random data on the Nexus 5, and the compared the results to the fastest implementation. In the following table, a lower runtime is better, with the fastest implementation getting a relative runtime of 1.
Execution environment
Options
Relative runtime (lower is better)
gcc 4.8
1.00
gcc 4.8
(LOCAL_ARM_NEON := true) -ffast-math -O3
1.02
gcc 4.8
-ffast-math -O3
1.05
clang 3.4
(LOCAL_ARM_NEON := true) -ffast-math -O3
1.27
clang 3.4
-ffast-math -O3
1.42
clang 3.4
1.43
ART (manually-optimized)
2.22
Dalvik (manually-optimized)
2.87
ART (normal code)
7.99
Dalvik (normal code)
17.78
The statically-compiled C code gave the best execution times, followed by ART and then by Dalvik. The C code uses JNI via GetShortArrayRegion and SetShortArrayRegion to marshal the data from Java to C, and then back from C to Java once processing has completed.
The best performance came courtesy of GCC 4.8, with little variation between the different additional optimization options. Clang’s ARM builds are not quite as optimized as GCC’s; toggling LOCAL_ARM_NEON := true in the NDK makefile also makes a clear difference in performance.
Even the slowest native build using clang is not more than 43% slower than the best native build using gcc. Once we switch to Java, the variance starts to increase significantly, with the best runtime about 2.2x slower than native code, and the worst runtime a staggering 17.8x slower.
What explains the large difference? For one, it appears that both ART and Dalvik are limited in the amount of static optimizations that they are capable of. This is understandable in the case of Dalvik, since it uses a JIT and it’s also much older, but it is disappointing in the case of ART, since it uses ahead-of-time compilation.
Is there a way to speed up the Java code? I decided to try it out, by applying the same static optimizations I would have expected the compiler to do, like converting modulo to bit masks and inlining function calls. These changes resulted in one massive and hard to read function, but they also dramatically improved the runtime performance, with Dalvik speeding up from a 17.8x penalty to 2.9x, and ART speeding up from an 8.0x penalty to 2.2x.
The downside of this is that the code has to be abused to get this additional performance, and it still doesn’t come close to matching the ahead-of-time code generated by gcc and clang, which can surpass that performance without similar abuse of the code. The NDK is still a viable option for those looking for improved performance and more efficient code which consumes less battery over time.
Just for fun, I decided to try things out on a laptop with a 2.6 GHz Intel Core i7. For this table, the relative results are in the other direction, with 1x corresponding to the best time on the Nexus 5, 2x being twice as fast, and so on. The table starts with the best results first, as before.
Execution environment
Options
Relative speed (higher is better)
clang 3.4
-O3 -ffast-math -flto
8.38x
clang 3.4
-O3 -ffast-math
6.09x
Java SE 1.7u51 (manually-optimized)
-XX:+AggressiveOpts
5.25x
Java SE 1.6u65 (manually-optimized)
3.85x
Java SE 1.6 (normal code)
2.44x
As on the Nexus 5, the C code runs faster, but to Java’s credit, the gap between the best & worst result is less than 4x, which is much less variance than we see with Dalvik or ART. Java 1.6 and 1.7 are very close to each other, unless “-XX:+AggressiveOpts” is used; with that option enabled, 1.7 is able to pull ahead.
There is still an unfortunate gap between the “normal” code and the manually-optimized code, which really should be closable with static analysis and inlining.
The other interesting result is that the gap between mobile and PC is closing over time, and even more so if you take power consumption into account. It’s quite impressive to see that as far as single-core performance goes, the PC and smartphone are closer than ever.
Conclusion
Recent Android devices are getting very powerful, and with the new ART runtime, common Java code can be executed quickly enough to keep user interfaces responsive and users happy.
Sometimes, though, we need to go further, and write demanding code that needs to run quickly and efficiently. With the latest Android devices, these algorithms may be able to run quickly enough in the Dalvik VM or with ART, but then we have to ask ourselves: is the benefit of using a single language worth the cost of lower performance? This isn’t just an academic question: lower performance means that we need to ask our users to give us more CPU cycles, which shortens their device’s battery life, heats up their phones, and makes them wait longer for results, and all because we didn’t want to write the code in another language.
For these reasons, writing some of our code in C/C++, FORTRAN, or another native language can still make a lot of sense.
Since all of the Java runtimes tested don’t exploit static optimization opportunities as well as it seems that they could, here is an optimized version that has been inlined and has the modulo replaced with a bit mask:
package com.example.perftest;
public class DspJavaManuallyOptimized {
public static class FilterState {
static final int size = 16;
final double input[] = new double[size];
final double output[] = new double[size];
int current;
}
public static void applyLowpass(FilterState filterState, short[] input, short[] output, int length) {
for (int i = 0; i < length; ++i) {
filterState.input[(filterState.current + 0) & (FilterState.size - 1)] = input[i];
++filterState.current;
final double[] x = filterState.input;
final double[] y = filterState.output;
y[(filterState.current + 0) & (FilterState.size - 1)] =
( 1.0 * (1.0 / 6.928330802e+06) * (x[(filterState.current + -10) & (FilterState.size - 1)] + x[(filterState.current + -0) & (FilterState.size - 1)]))
+ ( 10.0 * (1.0 / 6.928330802e+06) * (x[(filterState.current + -9) & (FilterState.size - 1)] + x[(filterState.current + -1) & (FilterState.size - 1)]))
+ ( 45.0 * (1.0 / 6.928330802e+06) * (x[(filterState.current + -8) & (FilterState.size - 1)] + x[(filterState.current + -2) & (FilterState.size - 1)]))
+ (120.0 * (1.0 / 6.928330802e+06) * (x[(filterState.current + -7) & (FilterState.size - 1)] + x[(filterState.current + -3) & (FilterState.size - 1)]))
+ (210.0 * (1.0 / 6.928330802e+06) * (x[(filterState.current + -6) & (FilterState.size - 1)] + x[(filterState.current + -4) & (FilterState.size - 1)]))
+ (252.0 * (1.0 / 6.928330802e+06) * x[(filterState.current + -5) & (FilterState.size - 1)])
+ ( -0.4441854896 * y[(filterState.current + -10) & (FilterState.size - 1)])
+ ( 4.2144719035 * y[(filterState.current + -9) & (FilterState.size - 1)])
+ ( -18.5365677633 * y[(filterState.current + -8) & (FilterState.size - 1)])
+ ( 49.7394321983 * y[(filterState.current + -7) & (FilterState.size - 1)])
+ ( -90.1491003509 * y[(filterState.current + -6) & (FilterState.size - 1)])
+ ( 115.3235358151 * y[(filterState.current + -5) & (FilterState.size - 1)])
+ (-105.4969191433 * y[(filterState.current + -4) & (FilterState.size - 1)])
+ ( 68.1964705422 * y[(filterState.current + -3) & (FilterState.size - 1)])
+ ( -29.8484881821 * y[(filterState.current + -2) & (FilterState.size - 1)])
+ ( 8.0012026712 * y[(filterState.current + -1) & (FilterState.size - 1)]);
output[i] = (short) Math.max(Short.MIN_VALUE, Math.min(Short.MAX_VALUE, (short) filterState.output[(filterState.current + 0) & (FilterState.size - 1)]));
}
}
}
The following post is based on a paper generously contributed by Jerome Huck, a senior aerospace/defence engineer, scientist, and author. A link to figures and the code can be found at the bottom of this post.
So you want to run some heavy-duty algorithms on your Android device, and you’re wondering what is the best environment to use, and whether your Nexus 7 tablet would be up to the job. In this post, based upon a paper generously contributed by Jerome Huck, a senior aerospace engineer & scientist, we’ll take a look at a test involving some heavy-duty computational fluid dynamics equations, and we’ll compare the execution times on a PC and a Nexus 7 tablet.
Implementation languages
Which language & development environment is the best fit? The Eclipse SDK is one obvious choice to go, with development usually done in Java. Unlocking additional performance through native C & C++ code can also be done via the Native Development Kit (NDK), though this adds complexity due to the mixing of Java, C/C++, and JNI glue code.
What if you want to develop directly on your device? Thanks to the openness of Google Play, there are many options available. The Java AIDE will allow you to write, compile and run programs directly on your Android tablet.
For native performance, C/C++ are available through C4DROID and CCTOOLS, an implementation of the GNU GCC 4.8.1 compiler. Fortran is also available for download from CCTOOLS’s menu.
Python development is available via QPython or Kivy. QPython implements the Python language but is still in beta stage; the Kivy Launcher enables you to run Kivy applications, an open source Python library for rapid development. Kivy applications can also make use of innovative user interfaces, including multi-touch apps.
So, just how powerful is your Nexus 7? Java, Basic, C/C++, Python and Fortran all seem like good candidates to evaluate the power of a Nexus 7 with a test case.
The Test Case
The test developed by Jerome involves some heavy-duty math, of the type often employed by scientists and engineers. Here are the details, as specified by Jerome and edited for formatting within this post:
For evaluating the performance, let’s use a test case using computational fluid dynamics algorithms, including Navier-Stokes fluid equations, the Maxwell electromagnetism equations, forming the magnetohydrodynamics (MHD) set of equations. The original Fortran code was published in An Introduction to Computational Fluid Mechanics by Chuen-Yen-Chow, in 1983. The MHD stationary flow calculation is no longer included in the 2011 update by Biringen and Chow, but the details pertaining to the equations discretization, stability analysis, and so on can still be found in their Benard and Taylor instabilities example of the instationary solution of Navier-Stokes equations coupled with the temperature equation.
For simplicity, a stream-vorticity formulation is used. Standard boundary conditions, or even simplified ones, are used, with a value or derivative given. Discretization of the nonlinear terms in the Navier-Stokes, the one involving the velocity components, was, historically, a source of problems. The numerical scheme has to properly capture the flow direction.
Upwind differencing form solves this problem. The spatial difference is on the upwind side of the point indexed (i,j). This numerical scheme is only first order by reference to a Taylor series expansion. The second order upwind schemes introduces non physical behaviour, such as oscillations. Total Variation Diminishing (TVD) schemes are a cure to this problem. They introduce stable, non-oscillatory, high order schemes, preserving monotonicity, with no overshot or undershoot for the solution. They are the result of more than 30 years of research in CFD.
The solution procedure is straightforward. The current flow, RH variable, is solved via the Laplace equation solver. Then the electromagnetic force, EM variable, is computed. Time stepping is used to find the solution of the flow until the convergence criteria are matched, error or maximum step. A Poisson solver is used.
Comments are given in the Fortran source code.
The results are presented for a Reynolds number of 50, a magnetic pressure number C of 0.3, using the upwind scheme.
Execution times on a PC
Before looking at the Nexus 7 results, let’s first compare the results on the PC. Here are the results that Jerome obtained on a i3 2.1 GHz laptop, running Windows 7 64-bit:
GNU Fortran
62ms
GNU GCC
78ms
Oracle Java JDK 7u45
150ms
PyPy 2.0
1020ms
Python 3.3.2
6780ms
For this particular run, Fortran is the best, with C a close second; the Java JDK also put in a good showing here. The interpreted languages are very disappointing, as expected.
Even with the slower execution times, some scientists are still moving some their code to Python; they want to benefit from the scripting capabilities of interpreted languages. Users don’t need to edit the source code to change the boundary equations or add a subroutine to solve a particular equation. FiPy, a finite volume code from NIST, uses this approach. However, most of the critical parts are still written in C or in Fortran.
Another approach is to use a dedicated language such the one implemented in FreeFem++, a partial differential equation solver. With this tool, a problem with one billion unknowns was solved in 2 minutes on the Curie Thin Node, a CEA machine. The CEA is the French Atomic Energy and Alternative Energies Commission.
What does the Nexus 7 has to offer?
Let’s now take a look at the results on a 1.2 GHz 2012 Nexus 7; the 2013 model, with its Qualcomm Snapdragon S4 Pro at 1.5 GHz, may boost these results a step further.
Fortran CCTOOLS with -march=armv7-a -mfloat-abi=softfp -mfpu=vfpv3 -03
70ms
Fortran CCTOOLS with -march=armv7-a -mfloat-abi=softfp -mfpu=vfpv3 -02
79ms
C99 C4DROID with -march=armv7-a -mfloat-abi=softfp -mfpu=vfpv3 -02 (64-bit floats)
120ms
C99 C4DROID with -march=armv7-a -mfloat-abi=softfp -mfpu=vfpv3 (32-bit floats)
380ms
C99 C4DROID with mfloat-abi=softfp (32-bit floats)
394ms
C99 C4DROID with -march=armv7-a -mfloat-abi=softfp -mfpu=vfpv3 (32-bit floats)
420ms
C99 C4DROID with mfloat-abi=softfp (64-bit floats)
450ms
C4DROID with -msoft-float (32-bit floats)
1163ms
C4DROID with -msoft-float (64-bit floats)
1500ms
Java compiled with Eclipse
1563ms
Java AIDE with dex optimizations
2100ms
Java AIDE
3030ms
QPython
24702ms
These are the best execution times. Some variance was seen with C4DROID, while CCTOOLS was more stable overall. As before, we can see the same ranking, with Fortran emerging as the leader, and C, Java, and Python following behind. With the proper compiler flags, CCTOOLS Fortran is even competitive against the PC, which is a very good result.
The Java results, on the other hand, are quite bad. Is it a fault of the Dalvik virtual machine? Results may improve with the ART runtime, but they’d have to improve dramatically to come close to the performance of optimized FORTRAN and C.
Python, with an execution time of over 24 seconds, can definitely be forgotten for serious scientific computations.
Verdict
The Nexus 7 2012 is very powerful on this particular test, when running Fortran or C code compiled to native machine code. Can these good results be extrapolated to more demanding programs, and software that needs more time to run?
The Nexus 7 tablets are very high-quality products, and Android is a smart and fun operating system to use. The 2012 model is already quite powerful, and the 2013 should see even better results; all that’s needed is a dedicated approach to unleash the power sleeping within those processors.
This blog post is based on work generously contributed by Jerome Huck, a senior aerospace/defence engineer, scientist, and author. Jerome graduated from the École nationale supérieure de l’aéronautique et de l’espace in Toulouse, and has worked on various projects including the Hermes space shuttle, Rafale fighter, and is the author of “The Fire of the Magicians“.
In this post in the air hockey series, we’re going to wrap up our air hockey project and add touch event handling and basic collision detection with support for Android, iOS, and emscripten.
The first thing we’ll do is update the core to add touch interaction to the game. We’ll first need to add some helper functions to a new core file called geometry.h.
These are a few typedefs that build upon linmath.h to add a few basic types that we’ll use in our code. Let’s wrap up geometry.h:
static inline int sphere_intersects_ray(Sphere sphere, Ray ray);
static inline float distance_between(vec3 point, Ray ray);
static inline void ray_intersection_point(vec3 result, Ray ray, Plane plane);
static inline int sphere_intersects_ray(Sphere sphere, Ray ray) {
if (distance_between(sphere.center, ray) < sphere.radius)
return 1;
return 0;
}
static inline float distance_between(vec3 point, Ray ray) {
vec3 p1_to_point;
vec3_sub(p1_to_point, point, ray.point);
vec3 p2_to_point;
vec3 translated_ray_point;
vec3_add(translated_ray_point, ray.point, ray.vector);
vec3_sub(p2_to_point, point, translated_ray_point);
// The length of the cross product gives the area of an imaginary
// parallelogram having the two vectors as sides. A parallelogram can be
// thought of as consisting of two triangles, so this is the same as
// twice the area of the triangle defined by the two vectors.
// http://en.wikipedia.org/wiki/Cross_product#Geometric_meaning
vec3 cross_product;
vec3_mul_cross(cross_product, p1_to_point, p2_to_point);
float area_of_triangle_times_two = vec3_len(cross_product);
float length_of_base = vec3_len(ray.vector);
// The area of a triangle is also equal to (base * height) / 2. In
// other words, the height is equal to (area * 2) / base. The height
// of this triangle is the distance from the point to the ray.
float distance_from_point_to_ray = area_of_triangle_times_two / length_of_base;
return distance_from_point_to_ray;
}
// http://en.wikipedia.org/wiki/Line-plane_intersection
// This also treats rays as if they were infinite. It will return a
// point full of NaNs if there is no intersection point.
static inline void ray_intersection_point(vec3 result, Ray ray, Plane plane) {
vec3 ray_to_plane_vector;
vec3_sub(ray_to_plane_vector, plane.point, ray.point);
float scale_factor = vec3_mul_inner(ray_to_plane_vector, plane.normal)
/ vec3_mul_inner(ray.vector, plane.normal);
vec3 intersection_point;
vec3 scaled_ray_vector;
vec3_scale(scaled_ray_vector, ray.vector, scale_factor);
vec3_add(intersection_point, ray.point, scaled_ray_vector);
memcpy(result, intersection_point, sizeof(intersection_point));
}
We’ll do a line-sphere intersection test to see if we’ve touched the mallet using our fingers or a mouse. Once we’ve grabbed the mallet, we’ll do a line-plane intersection test to determine where to place the mallet on the board.
We’ll now begin with the code for handling a touch press:
void on_touch_press(float normalized_x, float normalized_y) {
Ray ray = convert_normalized_2D_point_to_ray(normalized_x, normalized_y);
// Now test if this ray intersects with the mallet by creating a
// bounding sphere that wraps the mallet.
Sphere mallet_bounding_sphere = (Sphere) {
{blue_mallet_position[0],
blue_mallet_position[1],
blue_mallet_position[2]},
mallet_height / 2.0f};
// If the ray intersects (if the user touched a part of the screen that
// intersects the mallet's bounding sphere), then set malletPressed =
// true.
mallet_pressed = sphere_intersects_ray(mallet_bounding_sphere, ray);
}
static Ray convert_normalized_2D_point_to_ray(float normalized_x, float normalized_y) {
// We'll convert these normalized device coordinates into world-space
// coordinates. We'll pick a point on the near and far planes, and draw a
// line between them. To do this transform, we need to first multiply by
// the inverse matrix, and then we need to undo the perspective divide.
vec4 near_point_ndc = {normalized_x, normalized_y, -1, 1};
vec4 far_point_ndc = {normalized_x, normalized_y, 1, 1};
vec4 near_point_world, far_point_world;
mat4x4_mul_vec4(near_point_world, inverted_view_projection_matrix, near_point_ndc);
mat4x4_mul_vec4(far_point_world, inverted_view_projection_matrix, far_point_ndc);
// Why are we dividing by W? We multiplied our vector by an inverse
// matrix, so the W value that we end up is actually the *inverse* of
// what the projection matrix would create. By dividing all 3 components
// by W, we effectively undo the hardware perspective divide.
divide_by_w(near_point_world);
divide_by_w(far_point_world);
// We don't care about the W value anymore, because our points are now
// in world coordinates.
vec3 near_point_ray = {near_point_world[0], near_point_world[1], near_point_world[2]};
vec3 far_point_ray = {far_point_world[0], far_point_world[1], far_point_world[2]};
vec3 vector_between;
vec3_sub(vector_between, far_point_ray, near_point_ray);
return (Ray) {
{near_point_ray[0], near_point_ray[1], near_point_ray[2]},
{vector_between[0], vector_between[1], vector_between[2]}};
}
static void divide_by_w(vec4 vector) {
vector[0] /= vector[3];
vector[1] /= vector[3];
vector[2] /= vector[3];
}
This code first takes normalized touch coordinates which it receives from the Android, iOS or emscripten front ends, and then turns those touch coordinates into a 3D ray in world space. It then intersects the 3D ray with a bounding sphere for the mallet to see if we’ve touched the mallet.
Let’s continue with the code for handling a touch drag:
void on_touch_drag(float normalized_x, float normalized_y) {
if (mallet_pressed == 0)
return;
Ray ray = convert_normalized_2D_point_to_ray(normalized_x, normalized_y);
// Define a plane representing our air hockey table.
Plane plane = (Plane) {{0, 0, 0}, {0, 1, 0}};
// Find out where the touched point intersects the plane
// representing our table. We'll move the mallet along this plane.
vec3 touched_point;
ray_intersection_point(touched_point, ray, plane);
memcpy(previous_blue_mallet_position, blue_mallet_position,
sizeof(blue_mallet_position));
// Clamp to bounds
blue_mallet_position[0] =
clamp(touched_point[0], left_bound + mallet_radius, right_bound - mallet_radius);
blue_mallet_position[1] = mallet_height / 2.0f;
blue_mallet_position[2] =
clamp(touched_point[2], 0.0f + mallet_radius, near_bound - mallet_radius);
// Now test if mallet has struck the puck.
vec3 mallet_to_puck;
vec3_sub(mallet_to_puck, puck_position, blue_mallet_position);
float distance = vec3_len(mallet_to_puck);
if (distance < (puck_radius + mallet_radius)) {
// The mallet has struck the puck. Now send the puck flying
// based on the mallet velocity.
vec3_sub(puck_vector, blue_mallet_position, previous_blue_mallet_position);
}
}
static float clamp(float value, float min, float max) {
return fmin(max, fmax(value, min));
}
Once we’ve grabbed the mallet, we move it across the air hockey table by intersecting the new touch point with the table to determine the new position on the table. We then move the mallet to that new position. We also check if the mallet has struck the puck, and if so, we use the movement distance to calculate the puck’s new velocity.
We next need to update the lines that initialize our objects inside on_surface_created() as follows:
The new linmath.h has merged in the custom code we added to our matrix_helper.h, so we no longer need that file. As part of those changes, our perspective method call in on_surface_changed() now needs the angle entered in radians, so let’s update that method call as follows:
We can then update on_draw_frame() to add the new movement code. Let’s first add the following to the top, right after the call to glClear():
// Translate the puck by its vector
vec3_add(puck_position, puck_position, puck_vector);
// If the puck struck a side, reflect it off that side.
if (puck_position[0] < left_bound + puck_radius
|| puck_position[0] > right_bound - puck_radius) {
puck_vector[0] = -puck_vector[0];
vec3_scale(puck_vector, puck_vector, 0.9f);
}
if (puck_position[2] < far_bound + puck_radius
|| puck_position[2] > near_bound - puck_radius) {
puck_vector[2] = -puck_vector[2];
vec3_scale(puck_vector, puck_vector, 0.9f);
}
// Clamp the puck position.
puck_position[0] =
clamp(puck_position[0], left_bound + puck_radius, right_bound - puck_radius);
puck_position[2] =
clamp(puck_position[2], far_bound + puck_radius, near_bound - puck_radius);
// Friction factor
vec3_scale(puck_vector, puck_vector, 0.99f);
This code will update the puck’s position and cause it to go bouncing around the table. We’ll also need to add the following after the call to mat4x4_mul(view_projection_matrix, projection_matrix, view_matrix);:
With these changes in place, we now need to link in the touch events from each platform. We’ll start off with Android:
MainActivity.java
In MainActivity.java, we first need to update the way that we create the renderer in onCreate():
final RendererWrapper rendererWrapper = new RendererWrapper(this);
// ...
glSurfaceView.setRenderer(rendererWrapper);
Let’s add the touch listener:
glSurfaceView.setOnTouchListener(new OnTouchListener() {
@Override
public boolean onTouch(View v, MotionEvent event) {
if (event != null) {
// Convert touch coordinates into normalized device
// coordinates, keeping in mind that Android's Y
// coordinates are inverted.
final float normalizedX = (event.getX() / (float) v.getWidth()) * 2 - 1;
final float normalizedY = -((event.getY() / (float) v.getHeight()) * 2 - 1);
if (event.getAction() == MotionEvent.ACTION_DOWN) {
glSurfaceView.queueEvent(new Runnable() {
@Override
public void run() {
rendererWrapper.handleTouchPress(normalizedX, normalizedY);
}});
} else if (event.getAction() == MotionEvent.ACTION_MOVE) {
glSurfaceView.queueEvent(new Runnable() {
@Override
public void run() {
rendererWrapper.handleTouchDrag(normalizedX, normalizedY);
}});
}
return true;
} else {
return false;
}
}});
This touch listener takes the incoming touch events from the user, converts them into normalized coordinates in OpenGL’s normalized device coordinate space, and then calls the renderer wrapper which will pass the event on into our native code.
RendererWrapper.java
We’ll need to add the following to RendererWrapper.java:
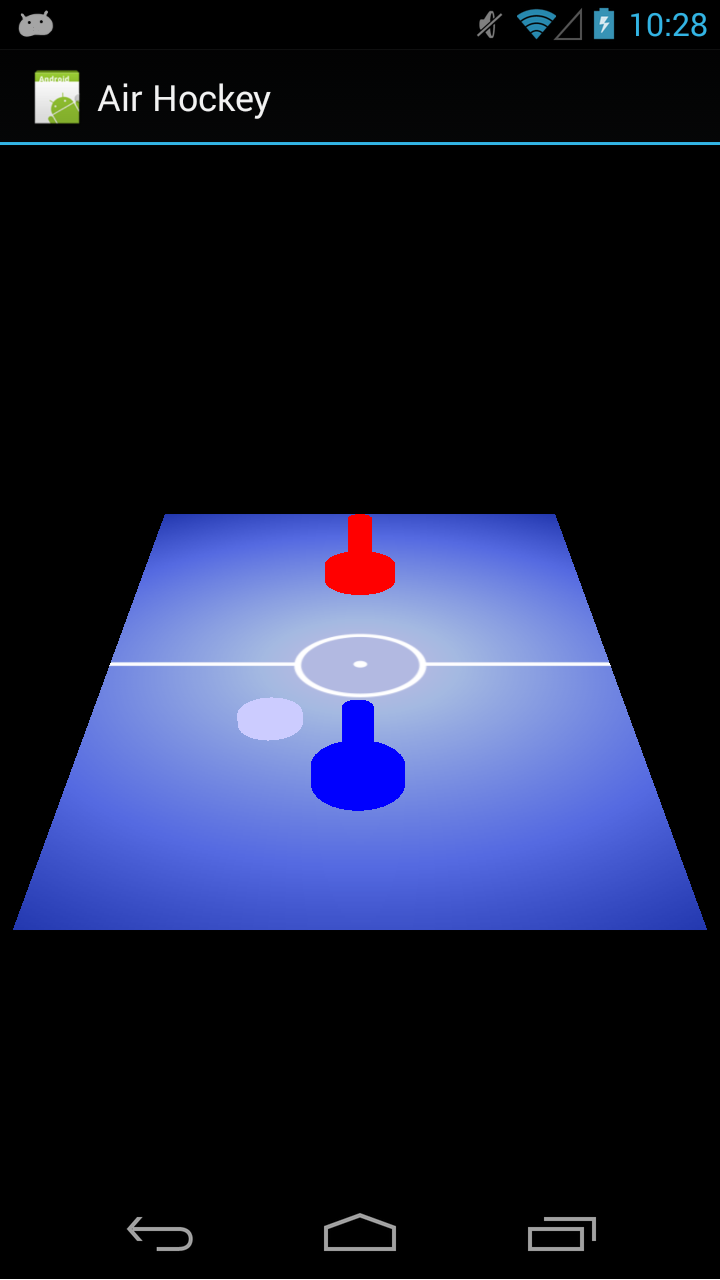
We now have everything in place for Android, and if we run the app, it should look similar to as seen below:
Air Hockey with touch, running on a Galaxy Nexus
Adding support for iOS
To add support for iOS, we need to update ViewController.m and add support for touch events. To do that and update the frame rate at the same time, let’s add the following to viewDidLoad: before the call to [self setupGL]:
To listen to the touch events, we need to override a few methods. Let’s add the following methods before - (void)glkView:(GLKView *)view drawInRect:(CGRect)rect:
This is similar to the Android code in that it takes the input touch event, converts it to OpenGL’s normalized device coordinate space, and then sends it on to our game code.
Our iOS app should look similar to the following image:
Air Hockey with touch, on iOS
Adding support for emscripten
Adding support for emscripten is just as easy. Let’s first add the following to the top of main.c:
static void handle_input();
// ...
int is_dragging;
At the beginning of do_frame(), add a call to handle_input();:
This code sets is_dragging depending on whether we just clicked the primary mouse button or if we’re currently dragging the mouse. Depending on the case, we’ll call either on_touch_press or on_touch_drag. The code to normalize the coordinates is the same as in Android and iOS, and indeed a case could be made to abstract out into the common game code, and just pass in the raw coordinates relative to the view size to that game code.
After compiling with emcc make, we should get output similar to the below:
Exploring further
That concludes our air hockey project! The full source code for this lesson can be found at the GitHub project. You can find a more in-depth look at the concepts behind the project from the perspective of Java Android in OpenGL ES 2 for Android: A Quick-Start Guide. For exploring further, there are many things you could add, like improved graphics, support for sound, a simple AI, multiplayer (on the same device), scoring, or a menu system.
Whether you end up using a commercial cross-platform solution like Unity or Corona, or whether you decide to go the independent route, I hope this series was helpful to you and most importantly, that you enjoy your future projects ahead and have a lot of fun with them. 🙂